Spring Batch Architecture
To help design and implement batch systems, basic batch application building blocks and patterns should be provided to the designers and programmers in the form of sample structure charts and code shells. When starting to design a batch job, the business l
docs.spring.io
초반을 제외하고 나머지는 문서를 번역한 내용입니다.
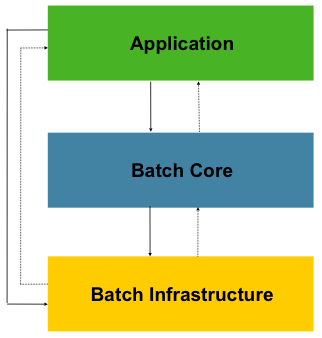
Spring Batch는 extensibility 과 다양한 사용자 그룹을 염두한 설계가 되어있다
이 architecture layered 아키텍쳐는 Application, Core, Infrastructure 세가지의 주요 상위 구성 요소를 강조한다
Application : Spring Batch 를 사용하여 개발자가 작성한 모든 batch작업 및 지정 코드가 포함되어 있다
Core : batch 작업을 시작하고 제어하는 runtime class가 포함되어있다(JobLauncher, Job 및 Step에 대한 구현)
>> 이 두가지가 공통 Infrastructure 위에 구축된다
Infrastructure : 응용 프로그램 개발자(ItemReader, ItemWriter 같은 readers and writers) 와 핵심 프레임워크 자체가 모두 사용하는 공통 판독기(: common readers and writers and services, 예를 들어 RetryTemplate 같은) 가 포함되어있다
General Batch Principles and Guidelines
배치 솔루션을 구축할 때 다음과 같은 주요 원칙, 지침 및 일반적인 고려 사항을 고려해야 합니다.
- 배치 아키텍처는 일반적으로 온라인 아키텍처에 영향을 미치며 그 반대도 마찬가지입니다. 가능한 경우 공통 빌딩 블록을 사용하여 아키텍처와 환경을 모두 염두에 두고 설계하십시오.
- 가능한 한 단순화하고 단일 배치 애플리케이션에서 복잡한 논리적 구조를 구축하지 마십시오.
- 데이터의 처리 및 저장을 물리적으로 가깝게 유지하십시오(즉, 처리가 발생하는 곳에 데이터를 유지하십시오).
- 시스템 리소스 사용, 특히 I/O를 최소화합니다. 내부 메모리에서 가능한 한 많은 작업을 수행하십시오.
- 응용 프로그램 I/O(SQL 문 분석)를 검토하여 불필요한 물리적 I/O를 피하십시오. 특히 다음 네 가지 일반적인 결함을 찾아야 합니다.
-
- 데이터를 한 번 읽고 작업 스토리지에 캐시하거나 보관할 수 있는 경우 모든 트랜잭션에 대한 데이터 읽기.
- 동일한 트랜잭션에서 이전에 데이터를 읽은 트랜잭션의 데이터를 다시 읽습니다.
- 불필요한 테이블 또는 인덱스 스캔을 유발합니다.
- WHERESQL 문의 절 에 키 값을 지정하지 않습니다 .
- 배치 실행에서 작업을 두 번 수행하지 마십시오. 예를 들어, 보고 목적으로 데이터 요약이 필요한 경우 데이터가 처음 처리될 때 저장된 합계를 증가시켜야(가능한 경우) 보고 응용 프로그램이 동일한 데이터를 다시 처리할 필요가 없습니다.
- 프로세스 중에 시간 소모적인 재할당을 방지하려면 배치 애플리케이션 시작 시 충분한 메모리를 할당하십시오.
- 항상 데이터 무결성과 관련하여 최악의 상황을 가정하십시오. 데이터 무결성을 유지하기 위해 적절한 검사를 삽입하고 유효성을 기록합니다.
- 가능한 경우 내부 유효성 검사를 위한 체크섬을 구현합니다. 예를 들어 플랫 파일에는 파일의 전체 레코드와 키 필드의 집계를 알려주는 트레일러 레코드가 있어야 합니다.
- 실제 데이터 볼륨이 있는 프로덕션 환경과 유사한 환경에서 가능한 한 빨리 스트레스 테스트를 계획하고 실행합니다.
- 대규모 배치 시스템에서는 특히 시스템이 연중무휴로 온라인 애플리케이션과 동시에 실행되는 경우 백업이 어려울 수 있습니다. 데이터베이스 백업은 일반적으로 온라인 설계에서 잘 관리되지만 파일 백업도 마찬가지로 중요하게 고려해야 합니다. 시스템이 플랫 파일에 의존하는 경우 파일 백업 절차가 마련되어 문서화되어야 할 뿐만 아니라 정기적으로 테스트되어야 합니다.
Batch Processing Strategies
배치 시스템을 설계하고 구현하는 데 도움이 되도록 기본 배치 애플리케이션 빌딩 블록 및 패턴을 샘플 구조 차트 및 코드 셸의 형태로 디자이너와 프로그래머에게 제공해야 합니다. 배치 작업 설계를 시작할 때 비즈니스 논리는 다음 표준 빌딩 블록을 사용하여 구현할 수 있는 일련의 단계로 분해되어야 합니다.
- 변환 응용 프로그램: 외부 시스템에서 제공하거나 외부 시스템을 위해 생성된 각 파일 유형에 대해 변환 응용 프로그램을 생성하여 제공된 거래 기록을 처리에 필요한 표준 형식으로 변환해야 합니다. 이러한 유형의 배치 애플리케이션은 부분적으로 또는 전체적으로 번역 유틸리티 모듈로 구성될 수 있습니다(기본 배치 서비스 참조).
- 검증 애플리케이션: 검증 애플리케이션은 모든 입력 및 출력 기록이 정확하고 일관성이 있는지 확인합니다. 유효성 검사는 일반적으로 파일 헤더 및 트레일러, 체크섬 및 유효성 검사 알고리즘, 레코드 수준 교차 검사를 기반으로 합니다.
- 추출 응용 프로그램: 추출 응용 프로그램은 데이터베이스 또는 입력 파일에서 레코드 집합을 읽고 미리 정의된 규칙에 따라 레코드를 선택하고 레코드를 출력 파일에 기록합니다.
- 응용 프로그램 추출/업데이트: 추출/업데이트 응용 프로그램은 데이터베이스 또는 입력 파일에서 레코드를 읽고 각 입력 레코드에서 찾은 데이터에 따라 데이터베이스 또는 출력 파일을 변경합니다.
- 응용 프로그램 처리 및 업데이트: 처리 및 업데이트 응용 프로그램은 추출 또는 유효성 검사 응용 프로그램의 입력 트랜잭션에 대한 처리를 수행합니다. 처리에는 일반적으로 처리에 필요한 데이터를 얻기 위해 데이터베이스를 읽고 잠재적으로 데이터베이스를 업데이트하고 출력 처리를 위한 레코드를 만드는 작업이 포함됩니다.
- 출력/형식 응용 프로그램: 출력/형식 응용 프로그램은 입력 파일을 읽고, 표준 형식에 따라 이 레코드에서 데이터를 재구성하고, 인쇄하거나 다른 프로그램이나 시스템으로 전송할 출력 파일을 생성합니다.
또한 앞서 언급한 빌딩 블록을 사용하여 구축할 수 없는 비즈니스 로직에 대해 기본 애플리케이션 셸을 제공해야 합니다.
기본 빌딩 블록 외에도 각 애플리케이션은 다음과 같은 하나 이상의 표준 유틸리티 단계를 사용할 수 있습니다.
- 정렬: 입력 파일을 읽고 레코드의 정렬 키 필드에 따라 레코드가 다시 정렬된 출력 파일을 생성하는 프로그램입니다. 정렬은 일반적으로 표준 시스템 유틸리티에 의해 수행됩니다.
- 분할: 단일 입력 파일을 읽고 필드 값을 기반으로 여러 출력 파일 중 하나에 각 레코드를 쓰는 프로그램입니다. 분할은 매개변수 기반 표준 시스템 유틸리티에 의해 조정되거나 수행될 수 있습니다.
- 병합: 여러 입력 파일에서 레코드를 읽고 입력 파일에서 결합된 데이터로 하나의 출력 파일을 생성하는 프로그램입니다. 병합은 매개변수 기반 표준 시스템 유틸리티로 조정하거나 수행할 수 있습니다.
배치 애플리케이션은 입력 소스별로 추가로 분류할 수 있습니다.
- 데이터베이스 기반 애플리케이션은 데이터베이스에서 검색된 행 또는 값에 의해 구동됩니다.
- 파일 기반 애플리케이션은 파일에서 검색된 레코드 또는 값에 의해 구동됩니다.
- 메시지 기반 애플리케이션은 메시지 큐에서 검색된 메시지에 의해 구동됩니다.
모든 배치 시스템의 기초는 처리 전략입니다. 전략 선택에 영향을 미치는 요소에는 예상 배치 시스템 볼륨, 온라인 시스템 또는 다른 배치 시스템과의 동시성, 사용 가능한 배치 윈도우가 포함됩니다. (더 많은 기업이 24x7 가동을 원하면서 명확한 배치 윈도우가 사라지고 있습니다.)
배치에 대한 일반적인 처리 옵션은 다음과 같습니다(구현 복잡성이 증가하는 순서대로).
- 오프라인 모드에서 배치 창 동안의 정상적인 처리.
- 동시 배치 또는 온라인 처리.
- 다양한 배치 실행 또는 작업을 동시에 병렬 처리합니다.
- 파티셔닝(같은 작업의 여러 인스턴스를 동시에 처리).
- 이전 옵션의 조합입니다.
이러한 옵션 중 일부 또는 전부는 상용 스케줄러에서 지원할 수 있습니다.
이 섹션의 나머지 부분에서는 이러한 처리 옵션에 대해 자세히 설명합니다. 일반적으로 배치 프로세스에서 채택하는 커밋 및 잠금 전략은 수행되는 처리 유형에 따라 다르며 온라인 잠금 전략도 동일한 원칙을 사용해야 합니다. 따라서 배치 아키텍처는 전체 아키텍처를 설계할 때 단순히 나중에 생각할 수 없습니다.
잠금 전략은 일반 데이터베이스 잠금만 사용하거나 아키텍처에서 추가 사용자 정의 잠금 서비스를 구현하는 것일 수 있습니다. 잠금 서비스는 데이터베이스 잠금(예: 필요한 정보를 전용 데이터베이스 테이블에 저장)을 추적하고 데이터베이스 작업을 요청하는 응용 프로그램에 권한을 부여하거나 거부합니다. 재시도 논리는 잠금 상황의 경우 배치 작업 중단을 방지하기 위해 이 아키텍처로 구현될 수도 있습니다.
1. 배치 창에서 일반 처리 업데이트 중인 데이터가 온라인 사용자나 다른 배치 프로세스에 필요하지 않은 별도의 배치 창에서 실행되는 간단한 배치 프로세스의 경우 동시성은 문제가 되지 않으며 종료 시 단일 커밋을 수행할 수 있습니다. 배치 실행.
대부분의 경우 보다 강력한 접근 방식이 더 적합합니다. 배치 시스템은 복잡도와 처리하는 데이터 양 측면에서 시간이 지남에 따라 증가하는 경향이 있습니다. 잠금 전략이 없고 시스템이 여전히 단일 커밋 지점에 의존하는 경우 배치 프로그램을 수정하는 것이 어려울 수 있습니다. 따라서 가장 단순한 배치 시스템을 사용하는 경우에도 재시작-복구 옵션에 대한 커밋 논리의 필요성과 이 섹션의 뒷부분에서 설명하는 더 복잡한 경우에 관한 정보를 고려해야 합니다.
2. 동시 배치 또는 온라인 처리 온라인 사용자가 동시에 업데이트할 수 있는 데이터를 처리하는 배치 애플리케이션은 온라인 사용자가 요구할 수 있는 데이터(데이터베이스 또는 파일)를 몇 초 이상 잠그지 않아야 합니다. . 또한 몇 번의 트랜잭션이 끝날 때마다 데이터베이스에 업데이트를 커밋해야 합니다. 이렇게 하면 다른 프로세스에서 사용할 수 없는 데이터 부분과 데이터를 사용할 수 없는 경과 시간이 최소화됩니다.
물리적 잠금을 최소화하는 또 다른 옵션은 낙관적 잠금 패턴 또는 비관적 잠금 패턴을 사용하여 논리적 행 수준 잠금을 구현하는 것입니다.
- 낙관적 잠금은 레코드 경합 가능성이 낮다고 가정합니다. 일반적으로 배치 및 온라인 처리에서 동시에 사용되는 각 데이터베이스 테이블에 타임스탬프 열을 삽입하는 것을 의미합니다. 애플리케이션이 처리를 위해 행을 가져올 때 타임스탬프도 가져옵니다. 그런 다음 애플리케이션이 처리된 행을 업데이트하려고 시도하면 업데이트는 절의 원래 타임스탬프를 사용합니다 WHERE. 타임스탬프가 일치하면 데이터와 타임스탬프가 업데이트됩니다. 타임스탬프가 일치하지 않으면 다른 애플리케이션이 가져오기와 업데이트 시도 사이에 동일한 행을 업데이트했음을 나타냅니다. 따라서 업데이트를 수행할 수 없습니다.
- 비관적 잠금은 레코드 경합 가능성이 높다고 가정하는 잠금 전략이므로 검색 시 물리적 또는 논리적 잠금을 얻어야 합니다. 비관적 논리적 잠금 유형 중 하나는 데이터베이스 테이블의 전용 잠금 열을 사용합니다. 애플리케이션이 업데이트할 행을 검색할 때 잠금 열에 플래그를 설정합니다. 플래그가 있으면 동일한 행을 검색하려는 다른 응용 프로그램이 논리적으로 실패합니다. 플래그를 설정하는 애플리케이션이 행을 업데이트하면 플래그도 지워지므로 다른 애플리케이션에서 해당 행을 검색할 수 있습니다. 예를 들어 데이터베이스 잠금(예:SELECT FOR UPDATE). 또한 이 방법은 레코드가 잠겨 있는 동안 사용자가 점심을 먹으러 가는 경우 잠금을 해제하는 시간 제한 메커니즘을 구축하는 것이 다소 쉽다는 점을 제외하면 물리적 잠금과 동일한 단점이 있습니다.
이러한 패턴은 일괄 처리에 반드시 적합하지는 않지만 동시 일괄 처리 및 온라인 처리(예: 데이터베이스가 행 수준 잠금을 지원하지 않는 경우)에 사용될 수 있습니다. 일반적으로 낙관적 잠금은 온라인 애플리케이션에 더 적합하고 비관적 잠금은 배치 애플리케이션에 더 적합합니다. 논리적 잠금이 사용될 때마다 논리적 잠금으로 보호되는 데이터 엔터티에 액세스하는 모든 응용 프로그램에 대해 동일한 체계를 사용해야 합니다.
이 두 솔루션 모두 단일 레코드 잠금만 처리합니다. 종종 논리적으로 관련된 레코드 그룹을 잠가야 할 수도 있습니다. 물리적 잠금을 사용하면 잠재적인 교착 상태를 피하기 위해 매우 신중하게 관리해야 합니다. 논리적 잠금을 사용하면 일반적으로 보호하려는 논리적 레코드 그룹을 이해하고 잠금이 일관되고 교착 상태가 아님을 보장할 수 있는 논리적 잠금 관리자를 구축하는 것이 가장 좋습니다. 이 논리적 잠금 관리자는 일반적으로 잠금 관리, 경합 보고, 시간 초과 메커니즘 및 기타 문제를 위해 자체 테이블을 사용합니다.
3. 병렬 처리 병렬 처리를 사용하면 여러 배치 실행 또는 작업을 병렬로 실행하여 전체 배치 처리 경과 시간을 최소화할 수 있습니다. 작업이 동일한 파일, 데이터베이스 테이블 또는 인덱스 공간을 공유하지 않는 한 문제가 되지 않습니다. 그렇다면 분할된 데이터를 사용하여 이 서비스를 구현해야 합니다. 또 다른 옵션은 제어 테이블을 사용하여 상호 종속성을 유지하기 위한 아키텍처 모듈을 구축하는 것입니다. 제어 테이블에는 각 공유 리소스에 대한 행과 애플리케이션에서 사용 중인지 여부가 포함되어야 합니다. 배치 아키텍처 또는 병렬 작업의 애플리케이션은 해당 테이블에서 정보를 검색하여 필요한 리소스에 액세스할 수 있는지 여부를 결정합니다.
데이터 액세스가 문제가 아닌 경우 추가 스레드를 사용하여 병렬 처리를 수행하여 병렬 처리를 구현할 수 있습니다. 메인프레임 환경에서는 모든 프로세스에 적절한 CPU 시간을 보장하기 위해 전통적으로 병렬 작업 클래스가 사용되었습니다. 그럼에도 불구하고 솔루션은 실행 중인 모든 프로세스에 대한 시간 분할을 보장할 수 있을 만큼 충분히 견고해야 합니다.
병렬 처리의 다른 주요 문제에는 로드 균형 조정과 파일, 데이터베이스 버퍼 풀 등과 같은 일반 시스템 리소스의 가용성이 포함됩니다. 또한 제어 테이블 자체가 중요한 리소스가 되기 쉽습니다.
4. 파티셔닝 파티셔닝 을 사용하면 여러 버전의 대규모 배치 애플리케이션을 동시에 실행할 수 있습니다. 이것의 목적은 긴 배치 작업을 처리하는 데 필요한 경과 시간을 줄이는 것입니다. 성공적으로 분할할 수 있는 프로세스는 입력 파일을 분할하거나 기본 데이터베이스 테이블을 분할하여 다른 데이터 세트에 대해 응용 프로그램을 실행할 수 있는 프로세스입니다.
또한 분할된 프로세스는 할당된 데이터 세트만 처리하도록 설계되어야 합니다. 파티셔닝 아키텍처는 데이터베이스 설계 및 데이터베이스 파티셔닝 전략과 밀접하게 연결되어야 합니다. 데이터베이스 파티셔닝이 반드시 데이터베이스의 물리적 파티셔닝을 의미하는 것은 아닙니다(대부분의 경우 권장됨). 다음 이미지는 파티셔닝 방식을 보여줍니다.

아키텍처는 파티션 수를 동적으로 구성할 수 있을 만큼 충분히 유연해야 합니다. 자동 및 사용자 제어 구성을 모두 고려해야 합니다. 자동 구성은 입력 파일 크기 및 입력 레코드 수와 같은 매개변수를 기반으로 할 수 있습니다.
4.1 분할 방식 분할 방식을 선택하는 것은 사례별로 이루어져야 합니다. 다음 목록은 가능한 파티셔닝 접근 방식 중 일부를 설명합니다.
1. 기록 세트의 고정 및 분할
여기에는 입력 레코드 세트를 짝수 부분으로 나누는 작업이 포함됩니다(예: 각 부분이 전체 레코드 세트의 정확히 1/10을 갖는 10). 그런 다음 배치/추출 응용 프로그램의 한 인스턴스에서 각 부분을 처리합니다.
이 방법을 사용하려면 레코드 설정을 분할하기 위한 전처리가 필요합니다. 이 분할의 결과는 일괄 처리/추출 응용 프로그램에 대한 입력으로 사용할 수 있는 하한 및 상한 배치 번호로, 처리를 해당 부분으로만 제한합니다.
전처리는 레코드 집합의 각 부분의 경계를 계산하고 결정해야 하므로 큰 오버헤드가 될 수 있습니다.
2. 키 컬럼으로 나누기
여기에는 위치 코드와 같은 키 열로 설정된 입력 레코드를 분할하고 각 키의 데이터를 배치 인스턴스에 할당하는 작업이 포함됩니다. 이를 달성하기 위해 열 값은 다음 중 하나일 수 있습니다.
- 파티셔닝 테이블에 의해 배치 인스턴스에 할당됩니다(이 섹션의 뒷부분에서 설명).
- 값의 일부(예: 0000-0999, 1000-1999 등)로 배치 인스턴스에 할당됩니다.
옵션 1에서 새 값을 추가한다는 것은 새 값이 특정 인스턴스에 추가되도록 배치 또는 추출을 수동으로 재구성하는 것을 의미합니다.
옵션 2에서 이렇게 하면 모든 값이 배치 작업의 인스턴스에 포함됩니다. 그러나 하나의 인스턴스에서 처리되는 값의 수는 열 값의 분포에 따라 다릅니다(0000-0999 범위에는 많은 위치가 있고 1000-1999 범위에는 거의 없을 수 있음). 이 옵션에서는 분할을 염두에 두고 데이터 범위를 설계해야 합니다.
두 옵션 모두 배치 인스턴스에 대한 레코드의 최적 균등 분포를 실현할 수 없습니다. 사용되는 배치 인스턴스 수에 대한 동적 구성이 없습니다.
3. 견해에 의한 이별
이 접근 방식은 기본적으로 키 열을 기준으로 하지만 데이터베이스 수준에서 구분됩니다. 여기에는 레코드 집합을 뷰로 나누는 작업이 포함됩니다. 이러한 보기는 처리 중에 배치 애플리케이션의 각 인스턴스에서 사용됩니다. 분리는 데이터를 그룹화하여 수행됩니다.
이 옵션을 사용하면 배치 애플리케이션의 각 인스턴스가 기본 테이블 대신 특정 보기에 도달하도록 구성되어야 합니다. 또한 새 데이터 값을 추가하면 이 새 데이터 그룹이 뷰에 포함되어야 합니다. 인스턴스 수를 변경하면 보기가 변경되므로 동적 구성 기능이 없습니다.
4. 처리 표시기 추가
여기에는 표시기 역할을 하는 입력 테이블에 새 열을 추가하는 작업이 포함됩니다. 전처리 단계로 모든 지표는 미처리로 표시됩니다. 배치 애플리케이션의 레코드 가져오기 단계에서는 개별 레코드를 미처리로 표시한 상태에서 레코드를 읽으며, 읽은 후에는(잠금 상태로) 처리 중으로 표시합니다. 해당 레코드가 완료되면 표시기가 완료 또는 오류로 업데이트됩니다. 추가 열을 통해 레코드가 한 번만 처리되도록 보장하므로 변경 없이 배치 애플리케이션의 많은 인스턴스를 시작할 수 있습니다.
이 옵션을 사용하면 테이블의 I/O가 동적으로 증가합니다. 업데이트 배치 애플리케이션의 경우 쓰기가 발생해야 하므로 이러한 영향이 줄어듭니다.
5. 테이블을 플랫 파일로 추출
이 접근 방식에는 테이블을 플랫 파일로 추출하는 작업이 포함됩니다. 그런 다음 이 파일을 여러 세그먼트로 분할하고 배치 인스턴스에 대한 입력으로 사용할 수 있습니다.
이 옵션을 사용하면 테이블을 파일로 추출하고 분할하는 추가 오버헤드로 인해 다중 분할 효과가 취소될 수 있습니다. 파일 분할 스크립트를 변경하여 동적 구성을 수행할 수 있습니다.
6. 해싱 컬럼 사용
이 체계에는 드라이버 레코드를 검색하는 데 사용되는 데이터베이스 테이블에 해시 열(키 또는 인덱스)을 추가하는 작업이 포함됩니다. 이 해시 열에는 이 특정 행을 처리하는 배치 애플리케이션의 인스턴스를 결정하는 표시기가 있습니다. 예를 들어 시작할 배치 인스턴스가 세 개 있는 경우 'A' 표시기는 인스턴스 1에서 처리할 행을 표시하고 'B' 표시기는 인스턴스 2에서 처리할 행을 표시하고 'C' 표시기는 행을 표시합니다. 인스턴스 3에서 처리할 행을 표시합니다.
WHERE레코드를 검색하는 데 사용되는 절차에는 특정 지표로 표시된 모든 행을 선택하는 추가 절이 있습니다 . 이 테이블의 삽입에는 인스턴스 중 하나(예: 'A')로 기본 설정되는 마커 필드의 추가가 포함됩니다.
서로 다른 인스턴스 간에 로드를 재분배하는 것과 같이 지표를 업데이트하는 데 간단한 배치 애플리케이션이 사용됩니다. 충분히 많은 수의 새 행이 추가되면 이 일괄 처리를 실행하여(일괄 처리 기간을 제외하고 언제든지) 새 행을 다른 인스턴스에 재배포할 수 있습니다.
배치 애플리케이션의 추가 인스턴스는 새로운 수의 인스턴스와 함께 작동하도록 표시기를 재배포하기 위해 배치 애플리케이션을 실행하기만 하면 됩니다(이전 단락에서 설명한 대로).
4.2 데이터베이스 및 애플리케이션 설계 원칙
파티션된 데이터베이스 테이블에 대해 실행되고 키 열 접근 방식을 사용하는 다중 파티션된 애플리케이션을 지원하는 아키텍처에는 파티션 매개변수를 저장하기 위한 중앙 파티션 리포지토리가 포함되어야 합니다. 이것은 유연성을 제공하고 유지 보수성을 보장합니다. 리포지토리는 일반적으로 파티션 테이블이라는 단일 테이블로 구성됩니다.
파티션 테이블에 저장된 정보는 정적이며 일반적으로 DBA가 유지 관리해야 합니다. 이 테이블은 다중 파티션 응용 프로그램의 각 파티션에 대한 정보의 한 행으로 구성되어야 합니다. 테이블에는 프로그램 ID 코드, 파티션 번호(파티션의 논리적 ID), 이 파티션에 대한 데이터베이스 키 열의 낮은 값 및 이 파티션에 대한 데이터베이스 키 열의 높은 값에 대한 열이 있어야 합니다.
프로그램 시작 시 프로그램 id및 파티션 번호는 아키텍처(특히 제어 처리 tasklet)에서 애플리케이션으로 전달되어야 합니다. 키 열 접근 방식을 사용하는 경우 이러한 변수는 애플리케이션이 처리할 데이터 범위를 결정하기 위해 파티션 테이블을 읽는 데 사용됩니다. 또한 파티션 번호는 다음을 위해 처리 전반에 걸쳐 사용해야 합니다.
- 병합 프로세스가 제대로 작동하려면 출력 파일 또는 데이터베이스 업데이트에 추가하십시오.
- 일반 처리는 배치 로그에 보고하고 오류는 아키텍처 오류 처리기에 보고합니다.
4.3 교착 상태 최소화
응용 프로그램이 병렬로 실행되거나 분할되면 데이터베이스 리소스에 대한 경합 및 교착 상태가 발생할 수 있습니다. 데이터베이스 디자인 팀이 데이터베이스 디자인의 일부로 가능한 한 잠재적 경합 상황을 제거하는 것이 중요합니다.
또한 개발자는 데이터베이스 인덱스 테이블이 교착 상태 방지 및 성능을 염두에 두고 설계되었는지 확인해야 합니다.
교착 상태 또는 핫스팟은 로그 테이블, 제어 테이블 및 잠금 테이블과 같은 관리 또는 아키텍처 테이블에서 자주 발생합니다. 이들의 영향도 고려해야 합니다. 현실적인 스트레스 테스트는 아키텍처에서 가능한 병목 현상을 식별하는 데 중요합니다.
데이터에 대한 충돌의 영향을 최소화하기 위해 아키텍처는 데이터베이스에 연결하거나 교착 상태가 발생할 때 서비스(예: 대기 및 재시도 간격)를 제공해야 합니다. 즉, 특정 데이터베이스 반환 코드에 반응하고 즉각적인 오류를 발생시키는 대신 미리 결정된 시간 동안 기다렸다가 데이터베이스 작업을 다시 시도하는 기본 제공 메커니즘을 의미합니다.
4.4 매개변수 전달 및 유효성 검사
파티션 아키텍처는 애플리케이션 개발자에게 상대적으로 투명해야 합니다. 아키텍처는 다음을 포함하여 분할 모드에서 애플리케이션 실행과 관련된 모든 작업을 수행해야 합니다.
- 애플리케이션 시작 전에 파티션 매개변수 검색.
- 애플리케이션 시작 전에 파티션 매개변수 유효성 검사.
- 시작 시 애플리케이션에 매개변수 전달.
유효성 검사에는 다음을 확인하는 검사가 포함되어야 합니다.
- 응용 프로그램에는 전체 데이터 범위를 포함할 수 있는 충분한 파티션이 있습니다.
- 파티션 사이에 간격이 없습니다.
데이터베이스가 파티션된 경우 단일 파티션이 데이터베이스 파티션에 걸쳐 있지 않은지 확인하기 위해 일부 추가 유효성 검증이 필요할 수 있습니다.
또한 아키텍처는 파티션의 통합을 고려해야 합니다. 주요 질문은 다음과 같습니다.
- 다음 작업 단계로 이동하기 전에 모든 파티션을 완료해야 합니까?
- 파티션 중 하나가 중단되면 어떻게 됩니까?
'Web > spring' 카테고리의 다른 글
| [Spring Batch] The Domain Language of Batch - (2) Step (0) | 2023.03.12 |
|---|---|
| [Spring Batch] The Domain Language of Batch - (1) Job (0) | 2023.03.11 |
| [Spring Framework core] 1.10. Classpath Scanning and Managed Components (2) (0) | 2023.03.10 |
| [Spring Framework core] 1.10. Classpath Scanning and Managed Components (1) (0) | 2023.03.10 |
| [String Batch] FlatFileItemReader (0) | 2023.03.09 |